Lately uClassify has gotten a lot of attention and the user community has grown at a faster rate. We are getting more requests and inquires from our customers and it feels like machine learning is something that many people know of, not only the tech savvy geeks
Whats in the next update
For a couple of months now I’ve been reworking the both the front end and back end to make it easier to go forward. It feels like a necessity to get some of the tech up to date. After all the tech is at least six years old.
The site will be replaced with a modern bootstrap powered front end. Making it much more responsive and easy to maintain. There will also be a few new features in the first release, e.g. ability to upload files to train classifiers. It will also be possible to log in via Google, Twitter and Facebook.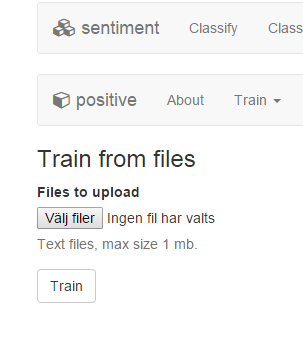
The backend is also being reworked to make it easier to work with. Those changes will be completely invisible to users and all public APIs will remain the same.
I hope to have all of this done before the end of June 2015.
Future plans
– Once all the new code is in place and the service is up and running I intend to add a complete JSON Api for the service. E.g. right now you need to use XML for batching calls.
– Open source C# and Java libs for calling the API.
– Add more and better classifiers. Today it’s easier to find good training data for classifiers.
– Classifier performance, I’ve a few ideas of how to improve the accuracy of the classifier further.

