Here is a short summary of 2017 and some glimpses into 2018.
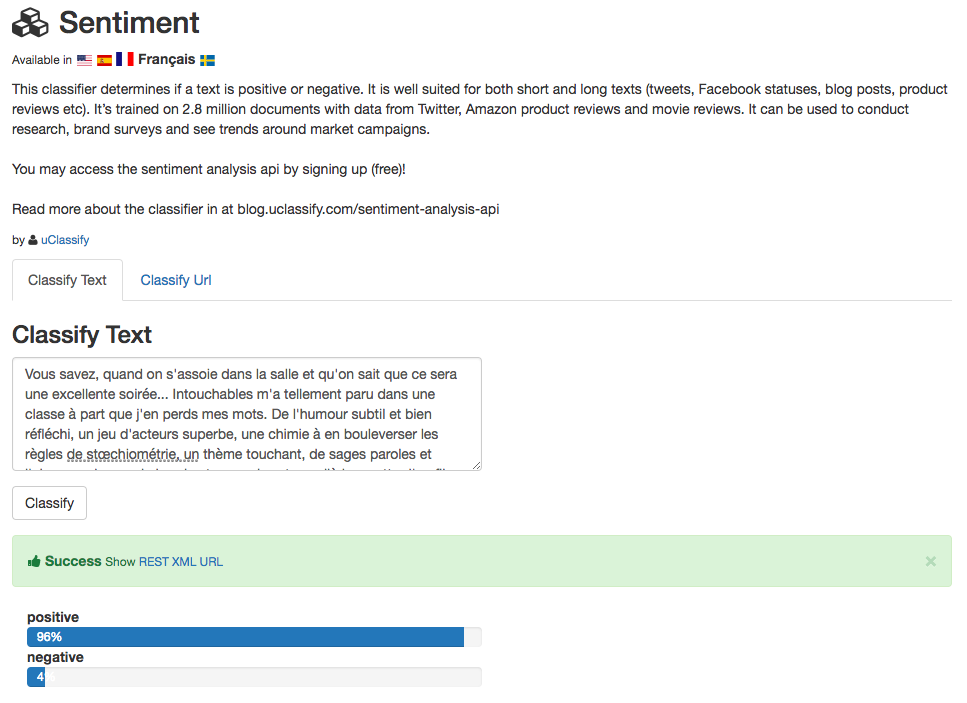
Last year was a good year for uClassify. The main theme was to offer classifiers in multiple languages (English, Spanish, French and Swedish). The task was non trivial and we decided to keep it in ‘beta’ for a long to make sure it works and scales as intended. Now we feel confident to move out of beta and start to promote the service.
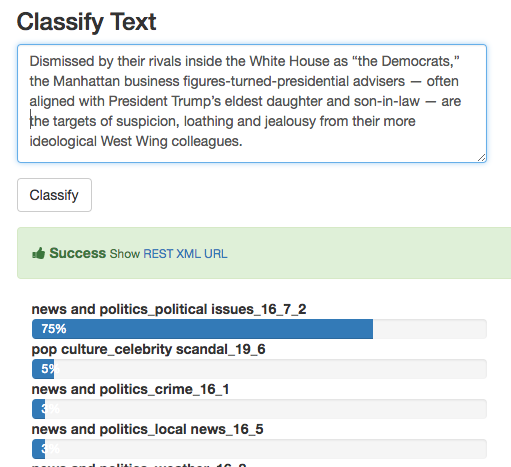
We created a few new classifiers for our users, the most popular are the IAB Taxonomy V2 and Language Detection classifiers (I am particularly proud of its capability to detect 370 different languages!) .
For the second half of 2017 I went on parental leave, during this time I mostly monitored uClassify, answered emails and pushed a few fixes.
As a hobby project I created a site with tons of generated number sequences, sequencedb.net, if you are into that kind of thing.
Thoughts about 2018
In the beginning of 2018 we will add more classifiers in different languages and move out of beta and do some promoting.
As for the next big features we are not entirely sure, there is a big request for URL batching, for different reasons we’ve been dodging this in the past, but it deserves a reconsideration.
During parental leave I played a lot with numeric, images and time series classification (as opposed to text). This is something I’m thinking of might find it’s way into the platform, although not sure in what form.
Another thing we should do is to publish api clients in different languages (Java, Python, C# etc).
During the coming month (my last month on parental leave) I’ll start with some of the tasks and set a plan for the rest of the year.
Happy new years everyone!
Jon