I am very happy to announce this performance update that means that classification will have better accuracy than before.
When I was building a new topic classifier based on the IAB taxonomy I did notice some weird behaviour for classes with much less training data than the others. As I started to investigate this I was able to understand how the overall classification could be improved, not only those with low training data. After weeks of testing different implementations I found a few improvements that significantly gave better results on the test datasets.
In short classifiers are much more robust and less sensitive to imbalanced data.
This update doesn’t affect any api endpoints it will only give you better probabilities.
I might write a short post on the technicalities of this update.
Disclaimer: I made this experiment out of curiosity and not academia. I’vent double checked the results and I have used arbitrary-feel-good-in-my-guts constants when running the tests.
In the last post I built a classifier from subtitles of movies that had failed and passed the Bechdel test. I used a dataset with about 2400 movie subtitles labeled whether or not they had passed the Bechdel test. The list of labels was obtained from bechdeltest.com.
In this post I will explore the inner workings of the classifier. What words and phrases reveal if a movie will pass or fail?
Lets just quickly recap what the Bechdel test is, it tests a movie for
The movie has to have at least two women in it,
who talk to each other,
about something besides a man.
Keywords from subtitles
It’s possible to extract keywords from classifiers. Keywords are discriminating indicators (words, phrases) for a specific class (passed or failed). There are many ways to weight them. I let the classifier sort every keyword according to the probability of belonging to a class.
Common, strong, keywords
To get a general overview we can disregard the most extreme keywords and instead consider keywords that appears more frequently. I extracted keywords that had occurred at least in 100 different movies (which is about 5% of the entire dataset).
To start with I looked at unigrams (single words) and removed non alphanumerical characters and transformed the text to lower case. To visualize the result I created two word clouds. One with keywords that indicate a failed test. One with keywords that are discriminative for a passed test.
Bigger words means higher probability of either failing or passing.
Subtitle keywords indicating a failed Bechdel test
Keywords like ‘lads’, ‘assault’, ‘rifle’, ’47’ (ak-47), and ‘russian’ seems to indicate a failed Bechdel test. Also words like ‘logic’, ‘solved’, ‘systems’, ‘capacity’ and ‘civilization’ are indicators of a failed Bechdel test.
Subtitle keywords indicating a passed Bechdel test
The word ‘boobs’ appears a lot more in subtitles of movies that passed the Bechdel tests than those which failed. I don’t know why, but I’ve double checked it. Overall it’s a lot of ‘lipstick’, ‘babies’, ‘washing’, ‘dresses’ and so on.
Keywords only from 2014 and 2015, did anything change?
The word clouds above are generated from 1892 up until now. So I wanted to check if anything had changed since. Below are two word clouds from 2014 and 2015 only. There were less training data (97 and 142 movies) and I only looked at words that appeared in 20 or more titles to avoid extreme features.
Recent subtitle keywords indicating a failed Bechdel test
Looking at the recent failed word cloud it seems like there are less lads, explosions and ak-47s. Also, Russia isn’t as scary anymore, goodbye the 80s. In general it’s less of the war stuff?
Recent subtitle keywords indicating a passed Bechdel test
From a quick glance it seems like something is different in the passed cloud too, we find words like ‘math’, ‘invented’, ‘developed’, ‘adventure’ and ‘robert’. Wait what Robert? So it seems like ‘Robert’ occurs in 20 movies that passed and 3 that failed last two years. Robert is probably noise (too small dataset). Furthermore, words like ‘washing’, ‘mall’, ‘slut’ and ‘shopping’ have been neutralized. Interestingly a new modern keyword ‘texted’ is used a lot in movies that passed the Bechdel test.
From a very informal point of view, it looks like we are moving in the right direction. But I think for a better understanding of how language has changed over time with a Bechdel -perspective it’s necessary to set up a more controlled experiment. One where you can follow keywords over time as they gain and lose usage. Like google trends, please feel free to explore it and let me know what you find out 😉
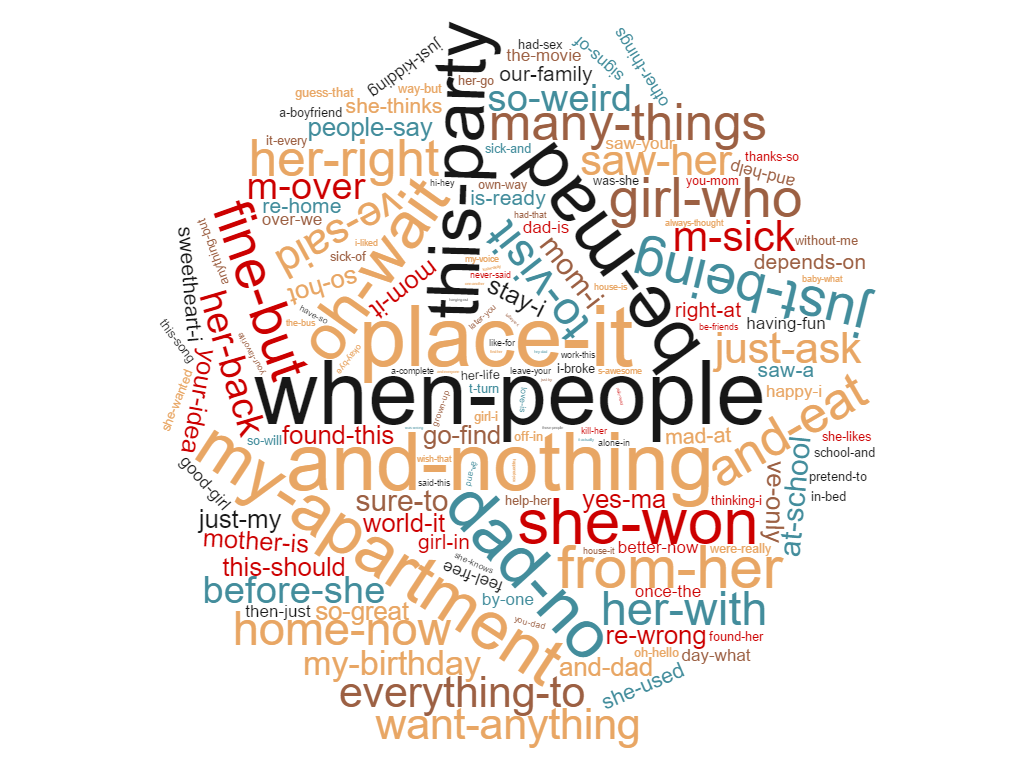
Looking at a recent movie, Mad Max: Fury Road
I decided to examine the subtitles in a recent movie that had passed the test, Mad Max: Fury Road. Todo this I trained a classifier with all subtitles since 1892, except the ones from Mad Max movies. Then extracted the keywords from the Mad Max: Fury Road subtitles.
Mad Max Fury Road subtitle keywords indicating a failed Bechdel testMad Max Fury Road subtitle keywords indicating a passed Bechdel test
This movie passes the Bechdel test. An interesting point is that despite the anecdotic presence word such as ‘babies’, ‘girly’ and ‘flowers’ (in the passed class) the words that surface are not linked to traditional femininity -unlike many other movies that have passed the test. Overall it’s much harder to differentiate between the two clouds.
If you haven’t seen it yet go and watch it, it’s very good!
Conclusion
If my experiment is carried out correctly, or at least good enough (read disclaimer at the top:) passing the Bechdel test doesn’t imply a gender equal movie. Even if it certifies the movie has…
At least two woman
that speak to each other
about something else than men …
…unfortunately this ‘something else than men’ often seems to be something linked to ‘traditional femininity’. The good news, when only looking at more recent data the trend seems to be getting more neutral, ‘washing’ is falling down on the list while ‘adventure’ rises.
It would be interesting to come up with a test that also captures the content as well as how women (and others) are represented. Designing the perfect test will probably be infinitely hard, especially for us humans. It seems like we have hard times on settling whether or not any movie is gender equal (just google any movie discussions). Perhaps with enough data, machine learning can design a test that reveal a multidimensional score of how well and why a movie passes or fails certain tests, not only examining gender but looking at all kinds of diversities.
Finally, just for the sake of clarity, I don’t think the Bechdel test is bad, it certainly helps us to think about women’s representation in movies. But maybe don’t always expect a non sexist, gender equal movie just because it passes the Bechdel test.
For bigrams I also removed non alphanumeric characters, that is why you can see some weird stuff like ‘you-don’ which should be ‘you-don’t’. However I decided to keep this because it can capture some interesting features like ‘s-fault’ (e.g. ‘dad’s fault’)
Space has been replaced by ‘-‘ so the word cloud word make sense.
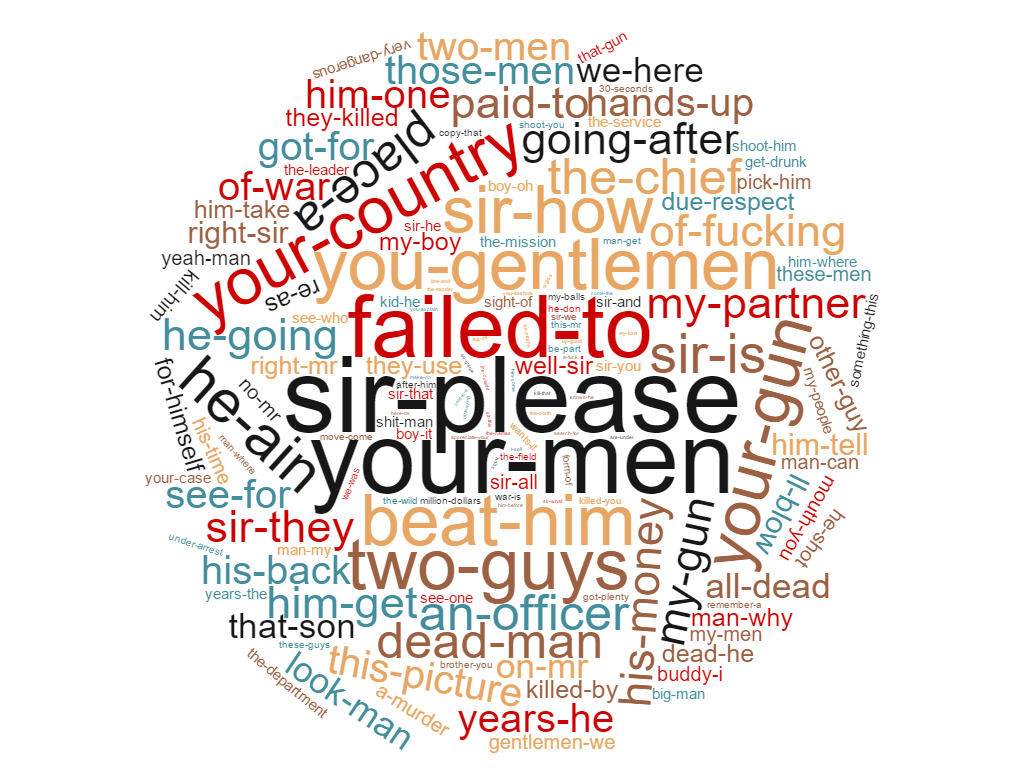
All time bigram keywords
Subtitle bigrams indicating a failed Bechdel testSubtitle bigrams indicating a passed Bechdel test
One interesting thing here is the ‘your men’ vs ‘you girls’. I will leave the analysis to you 😉
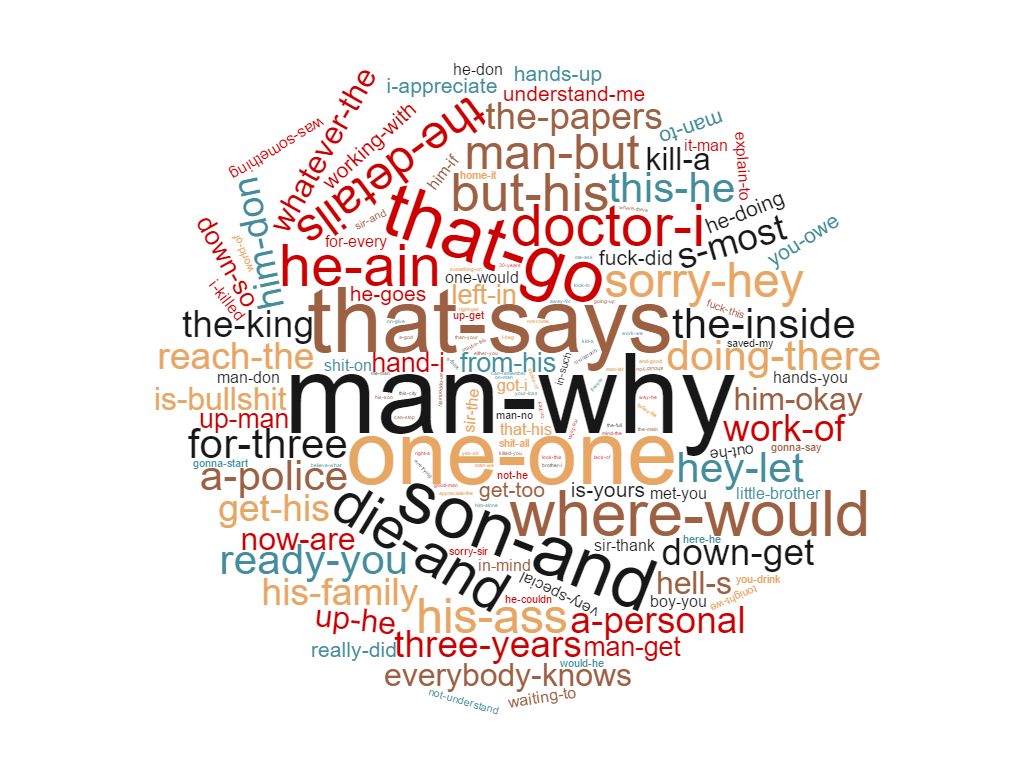
2014 and 2015 bigram keywords
Recent subtitle bigrams indicating a failed Bechdel testRecent subtitle bigrams indicating a passed Bechdel test
Doesn’t sound so hard to pass, does it? This test was introduced by Alison Bechdel in 1985 in one of her comics, ‘The rule‘.
The largest database of movies that has been Bechdel tested is on bechdeltest.com. The database contains over 6000 titles from 1892 up until now. How many percent do you think pass the Bechdel test overall? As I write this about 58% of the movies has passed the test. Statistics from here.
Being interested in machine learning and data I thought it would maybe be possible to find a textual correlation between movies that fail and pass the test.
To build a classifier that figures this out requires data. It needs labeled samples to learn from. It should be a list of films that passes and fails the test. The more the better. Then for each movie we need to extract features. Features could be the cover, the title, the description, the subtitles, the audio or anything that is in the movie.
Data & features
I was very happy when I found bechdeltest.com, it has a pretty extensive list exceeding 6000 movie titles with information of whether it passed the Bechtel test or not. Even better, it has a Bechtel test rating of 0-3, where 0) means it fails the first part of the test and 3) that it passes all tests.
Since I am dealing with text classifiers the natural choices for features were:
– The description
– The subtitles
– The title
The descriptions were retrieved using omdbapi.com api which gets the plot from imdb. I retrieved plots from 2433 failed and 3281 passed movies.
The subtitles were a bit more cumbersome to find, I did use about 2400 movies selected randomly and spent some time downloading them from various sites. Pweii.
Finally the training data for the title was easily obtained by just creating samples with the only the movie titles for each class. In total 2696 and 3669 movie titles.
Results
I setup an environment and ran 10-fold-cross-validation for all the data (train on 9/10 samples, test with 1/10 then rotate). For feature extraction I looked at case insensitive unigrams and bigrams.
I trained a classifier reading IMDB plots labeled whether or not the corresponding movie had passed the test. The classifier turned out to have an accuracy of 67% .
By only reading the subtitles uClassify was able to predict whether or not a movie would pass an accuracy of 68%.
One classifier was trained to only look on the movie titles. The accuracy of the classifier was about 55% and this is not surprising at all considering how small the training dataset is.
Finally, I mashed together the subtitles and plots into one classifier that showed a slight increase in accuracy of 69%.
Dataset
#Failed
#Passed
Accuracy
Plots
2433
3281
67%
Subtitles
1024
1262
68%
Titles
2696
3669
55%
Subtitles+plot
3457
4543
69%
The combined (subtitles+plots) classifier is available here, you can toss movie plots or subtitles (and probably scripts) at it and it will do its best to predict if it passes the Bechdel test or not.
Conclusion
The predictive accuracy of the classifier may not be the best, it certainly doesn’t figure out the 1-3 sub rules by just looking at unigrams and bigrams. But it does capture something to predict 70% correctly. I’m curious to find out exactly what it does make it decisions on and will make another blog post on this.
Since uClassify was launched back in 2008 we have seen many technological changes. Last year I modernised the site to use bootstrap as a foundation. Now it’s time to take the api to a more modern format.
Initially the uClassify api only had an XML endpoint, however over the years JSON has become more common and I have been getting more and more requests for REST endpoints with JSON format. The graph below shows google trends ‘json api’ (red) vs ‘xml api’ (blue)
XML API VS JSON API
Today I have launched a beta of the JSON REST API, changes may still occur but it will hopefully be finalised during Mars 2016.
You can find the documentation here, please feel free to leave feedback.
The old XML and URL API endpoints will of course continue to work as before.
Machine Learning is certainly picking up, we are getting a lot more users and requests and we are really excited by this. So we started 2016 by making an maintenance update, mostly fixes:
Fixed broken xml schema links
Fixed keyword extraction for classifiers using other than uni-grams (e.g. sentiment classifier)
The last major update has been running very smoothly, this is the first patch since!
Max request size limit increased
After feedback from the community I’ve increased the maximum allowed request size from 1MB to 3MB. I will monitor the servers and make sure this works fine. Maybe it’s possible to increase it further.
Max query string length increase
After the last update, when I updated the IIS server the default max request string url length was lower then previous. Thanks Liz who noticed this. I’ve not set the max size to 65kb.
Max free calls per day decreased
When I looked at the call statistics it didn’t make much sense to offer 5000 free calls per day. Most people aren’t even close to this, by lowering it to 1000 calls per day only a few will be affected, but most will not notice anything. This is also motivated by looking on competitors free limits and 1000 calls per day is still very generous. Let me know if you have any questions about this.
Bugs
Besides fixing some typos (thanks to everyone who reported) I’ve made it so you can’t publish untrained classifiers and fixed a so the front page buttons work better on small displays. I’ll also unpublished previous classifiers that are untrained and published.
Future
I am extremely happy with the performance of the new Sentiment classifier. It uses a new version of the classifier that looks at combinations of words among other things. Tests show that this type of classifier improves the performance of all tested data sets, therefore I am trying to figure out how to use it for all new classifiers, but it does require some work.
A Sentiment analyzer tells you if a text it’s positive or negative. For example “I love the new Mad Max Fury road” (positive) or “i am not impressed by the bike” (negative). The Sentiment classifier hosted by uClassify is very popular so I decided to spend some time on improving it.
The goal was to improve the classification accuracy, especially for short texts such as Twitter messages, Facebook statuses or other snippets while maintaining high quality results on texts with more information.
The old Sentiment classifier was built by 40k amazon product reviews. The straight forward way to improve a classifier is to add more data. Thanks to the Internet we were able to find multiple data sources we could train our classifier on. In fact it’s now trained on 2.8 million documents!
The results are good very good, the accuracy on large documents (reviews) went from about 75% to 83%. Tweets went from 63% to about 77%.
As a part of the uClassify upgrade I’ve recompiled the local server for 64-bit. This was necessary since I’m working on a huge classifier for sentiment and needed the corpus tool to be able to handle more then what 32-bit pointers could hold.
If you are running a local uClassify server, you can download the 64-bit (and 32-bit) here. The 64-bit server is already used in production for uClassify and should be pretty well tested by now.
The old uClassify site has been set to read-only and the database & classifier migration has been done. Now we are just waiting for the DNS to propagate over the nets before the new site can be taken into use. This time on an elastic IP so hopefully this we won’t have to do anymore of those ‘waiting’ operations in the future.
Hopefully it has been fully propagated within 24h.
Let me know if you have any trouble with your account.
Exciting times! I’ve decided to push the next update out on Thursday May the 14th (2015). Normally you won’t notice updates but this one is huge.
I’m migrating servers from old ‘Classic’ Amazon EC2 to their new cloudy thing. This will require a DNS update which takes time to propagate over internet before it’s completely done.
Read Only Mode during the transition
Since this also involves a database migration step, I will set the uClassify to ‘read-only’ until it’s done. This means that all the read calls (classify etc) should continue to work during the transition while write calls won’t go through (creating, training classifiers). You won’t be able to register as a new user during this time either. DNS updates usually takes about 48h.
What will be new
First, I’ve done extensive testing to make sure the API will behave exactly the same. If I have not missed anything your app will continue to work without any changes.
The major ‘visible’ changes are:
– A new responsive bootstrap UI (the vanilla theme, somehow cosmetics always ends up last on my prio lists 🙂
– To make it more secure the entire site will be in SSL (don’t worry all the API links without https:// will still work).
– It will be possible to sign in via Twitter, Facebook and Google.
– You can train classifiers by uploading files.
This is the first of a few major updates for uClassify, it doesn’t introduce much new cool fancy stuff but it’s a very important updates that paves the road for the stuff I actually want to add, such as an JSON api.
If you have any questions please don’t hesitate to contact me. (contact AT uclassify DOT com)