We have updated some of our most popular classifiers to give better results.
Our most popular classifier for sentiment has been updated to give better performance. The major difference is that the data has gone through a cleaning pass, removing non english texts (noise). And with a slightly improved feature extractor and optimized data we can expect better accuracy.
We’ve also updated the following popular classifiers to use a new feature extractor. The result is better accuracy.
We have constructed a language detector consisting of about 374 languages.
It can detect both living and extinct languages (e.g. English and Tupi), identify ancient and constructed (e.g. Latin and Klingon) and even different dialects.
Each language class has been named with its English name followed by an underscore and the corresponding ISO 639-3 three letter code. E.g.
Some of the rare languages (about 30) may have insufficient training data. The idea is to improve the classifier as more documents are gathered. Also we may add more languages in the future, so make sure your code can handle that.
Here is the full list of supported languages
Language Name
ISO 639-3
Type
Abkhazian
abk
living
Achinese
ace
living
Adyghe
ady
living
Afrihili
afh
constructed
Afrikaans
afr
living
Ainu
ain
living
Akan
aka
living
Albanian
sqi
living
Algerian Arabic
arq
living
Amharic
amh
living
Ancient Greek
grc
historical
Arabic
ara
living
Aragonese
arg
living
Armenian
hye
living
Arpitan
frp
living
Assamese
asm
living
Assyrian Neo-Aramaic
aii
living
Asturian
ast
living
Avaric
ava
living
Awadhi
awa
living
Aymara
aym
living
Azerbaijani
aze
living
Balinese
ban
living
Bambara
bam
living
Banjar
bjn
living
Bashkir
bak
living
Basque
eus
living
Bavarian
bar
living
Baybayanon
bvy
living
Belarusian
bel
living
Bengali
ben
living
Berber
ber
living
Bhojpuri
bho
living
Bishnupriya
bpy
living
Bislama
bis
living
Bodo
brx
living
Bosnian
bos
living
Breton
bre
living
Bulgarian
bul
living
Buriat
bua
living
Burmese
mya
living
Catalan
cat
living
Cebuano
ceb
living
Central Bikol
bcl
living
Central Huasteca Nahuatl
nch
living
Central Khmer
khm
living
Central Kurdish
ckb
living
Central Mnong
cmo
living
Chamorro
cha
living
Chavacano
cbk
living
Chechen
che
living
Cherokee
chr
living
Chinese
zho
living
Choctaw
cho
living
Chukot
ckt
living
Church Slavic
chu
ancient
Chuvash
chv
living
Coastal Kadazan
kzj
living
Cornish
cor
living
Corsican
cos
living
Cree
cre
living
Crimean Tatar
crh
living
Croatian
hrv
living
Cuyonon
cyo
living
Czech
ces
living
Danish
dan
living
Dhivehi
div
living
Dimli
diq
living
Dungan
dng
living
Dutch
nld
living
Dutton World Speedwords
dws
constructed
Dzongkha
dzo
living
Eastern Mari
mhr
living
Egyptian Arabic
arz
living
Emilian
egl
living
English
eng
living
Erzya
myv
living
Esperanto
epo
constructed
Estonian
est
living
Ewe
ewe
living
Extremaduran
ext
living
Faroese
fao
living
Fiji Hindi
hif
living
Finnish
fin
living
French
fra
living
Friulian
fur
living
Fulah
ful
living
Gagauz
gag
living
Galician
glg
living
Gan Chinese
gan
living
Ganda
lug
living
Garhwali
gbm
living
Georgian
kat
living
German
deu
living
Gilaki
glk
living
Gilbertese
gil
living
Goan Konkani
gom
living
Gothic
got
ancient
Guarani
grn
living
Guerrero Nahuatl
ngu
living
Gujarati
guj
living
Gulf Arabic
afb
living
Haitian
hat
living
Hakka Chinese
hak
living
Hausa
hau
living
Hawaiian
haw
living
Hebrew
heb
living
Hiligaynon
hil
living
Hindi
hin
living
Hmong Daw
mww
living
Hmong Njua
hnj
living
Ho
hoc
living
Hungarian
hun
living
Iban
iba
living
Icelandic
isl
living
Ido
ido
constructed
Igbo
ibo
living
Iloko
ilo
living
Indonesian
ind
living
Ingrian
izh
living
Interlingua
ina
constructed
Interlingue
ile
constructed
Iranian Persian
pes
living
Irish
gle
living
Italian
ita
living
Jamaican Creole English
jam
living
Japanese
jpn
living
Javanese
jav
living
Jinyu Chinese
cjy
living
Judeo-Tat
jdt
living
K’iche’
quc
living
Kabardian
kbd
living
Kabyle
kab
living
Kadazan Dusun
dtp
living
Kalaallisut
kal
living
Kalmyk
xal
living
Kamba
kam
living
Kannada
kan
living
Kara-Kalpak
kaa
living
Karachay-Balkar
krc
living
Karelian
krl
living
Kashmiri
kas
living
Kashubian
csb
living
Kazakh
kaz
living
Kekchķ
kek
living
Keningau Murut
kxi
living
Khakas
kjh
living
Khasi
kha
living
Kinyarwanda
kin
living
Kirghiz
kir
living
Klingon
tlh
constructed
Kölsch
ksh
living
Komi
kom
living
Komi-Permyak
koi
living
Komi-Zyrian
kpv
living
Kongo
kon
living
Korean
kor
living
Kotava
avk
constructed
Kumyk
kum
living
Kurdish
kur
living
Ladin
lld
living
Ladino
lad
living
Lakota
lkt
living
Lao
lao
living
Latgalian
ltg
living
Latin
lat
ancient
Latvian
lav
living
Laz
lzz
living
Lezghian
lez
living
Lįadan
ldn
constructed
Ligurian
lij
living
Lingala
lin
living
Lingua Franca Nova
lfn
constructed
Literary Chinese
lzh
historical
Lithuanian
lit
living
Liv
liv
living
Livvi
olo
living
Lojban
jbo
constructed
Lombard
lmo
living
Louisiana Creole
lou
living
Low German
nds
living
Lower Sorbian
dsb
living
Luxembourgish
ltz
living
Macedonian
mkd
living
Madurese
mad
living
Maithili
mai
living
Malagasy
mlg
living
Malay
zlm
living
Malay
msa
living
Malayalam
mal
living
Maltese
mlt
living
Mambae
mgm
living
Mandarin Chinese
cmn
living
Manx
glv
living
Maori
mri
living
Marathi
mar
living
Marshallese
mah
living
Mazanderani
mzn
living
Mesopotamian Arabic
acm
living
Mi’kmaq
mic
living
Middle English
enm
historical
Middle French
frm
historical
Min Nan Chinese
nan
living
Minangkabau
min
living
Mingrelian
xmf
living
Mirandese
mwl
living
Modern Greek
ell
living
Mohawk
moh
living
Moksha
mdf
living
Mon
mnw
living
Mongolian
mon
living
Morisyen
mfe
living
Moroccan Arabic
ary
living
Na
nbt
living
Narom
nrm
living
Nauru
nau
living
Navajo
nav
living
Neapolitan
nap
living
Nepali
npi
living
Nepali
nep
living
Newari
new
living
Ngeq
ngt
living
Nigerian Fulfulde
fuv
living
Niuean
niu
living
Nogai
nog
living
North Levantine Arabic
apc
living
North Moluccan Malay
max
living
Northern Frisian
frr
living
Northern Luri
lrc
living
Northern Sami
sme
living
Norwegian
nor
living
Norwegian Bokmål
nob
living
Norwegian Nynorsk
nno
living
Novial
nov
constructed
Nyanja
nya
living
Occitan
oci
living
Official Aramaic
arc
ancient
Ojibwa
oji
living
Old Aramaic
oar
ancient
Old English
ang
historical
Old Norse
non
historical
Old Russian
orv
historical
Old Saxon
osx
historical
Oriya
ori
living
Orizaba Nahuatl
nlv
living
Oromo
orm
living
Ossetian
oss
living
Ottoman Turkish
ota
historical
Palauan
pau
living
Pampanga
pam
living
Pangasinan
pag
living
Panjabi
pan
living
Papiamento
pap
living
Pedi
nso
living
Pennsylvania German
pdc
living
Persian
fas
living
Pfaelzisch
pfl
living
Picard
pcd
living
Piemontese
pms
living
Pipil
ppl
living
Pitcairn-Norfolk
pih
living
Polish
pol
living
Pontic
pnt
living
Portuguese
por
living
Prussian
prg
living
Pulaar
fuc
living
Pushto
pus
living
Quechua
que
living
Quenya
qya
constructed
Romanian
ron
living
Romansh
roh
living
Romany
rom
living
Rundi
run
living
Russia Buriat
bxr
living
Russian
rus
living
Rusyn
rue
living
Samoan
smo
living
Samogitian
sgs
living
Sango
sag
living
Sanskrit
san
ancient
Sardinian
srd
living
Saterfriesisch
stq
living
Scots
sco
living
Scottish Gaelic
gla
living
Serbian
srp
living
Serbo-Croatian
hbs
living
Seselwa Creole French
crs
living
Shona
sna
living
Shuswap
shs
living
Sicilian
scn
living
Silesian
szl
living
Sindarin
sjn
constructed
Sindhi
snd
living
Sinhala
sin
living
Slovak
slk
living
Slovenian
slv
living
Somali
som
living
South Azerbaijani
azb
living
Southern Sami
sma
living
Southern Sotho
sot
living
Spanish
spa
living
Sranan Tongo
srn
living
Standard Latvian
lvs
living
Standard Malay
zsm
living
Sumerian
sux
ancient
Sundanese
sun
living
Swabian
swg
living
Swahili
swa
living
Swahili
swh
living
Swati
ssw
living
Swedish
swe
living
Swiss German
gsw
living
Tagal Murut
mvv
living
Tagalog
tgl
living
Tahitian
tah
living
Tajik
tgk
living
Talossan
tzl
constructed
Talysh
tly
living
Tamil
tam
living
Tarifit
rif
living
Tase Naga
nst
living
Tatar
tat
living
Telugu
tel
living
Temuan
tmw
living
Tetum
tet
living
Thai
tha
living
Tibetan
bod
living
Tigrinya
tir
living
Tok Pisin
tpi
living
Tokelau
tkl
living
Tonga
ton
living
Tosk Albanian
als
living
Tsonga
tso
living
Tswana
tsn
living
Tulu
tcy
living
Tupķ
tpw
extinct
Turkish
tur
living
Turkmen
tuk
living
Tuvalu
tvl
living
Tuvinian
tyv
living
Udmurt
udm
living
Uighur
uig
living
Ukrainian
ukr
living
Umbundu
umb
living
Upper Sorbian
hsb
living
Urdu
urd
living
Urhobo
urh
living
Uzbek
uzb
living
Venda
ven
living
Venetian
vec
living
Veps
vep
living
Vietnamese
vie
living
Vlaams
vls
living
Vlax Romani
rmy
living
Volapük
vol
constructed
Võro
vro
living
Walloon
wln
living
Waray
war
living
Welsh
cym
living
Western Frisian
fry
living
Western Mari
mrj
living
Western Panjabi
pnb
living
Wolof
wol
living
Wu Chinese
wuu
living
Xhosa
xho
living
Xiang Chinese
hsn
living
Yakut
sah
living
Yiddish
yid
living
Yoruba
yor
living
Yue Chinese
yue
living
Zaza
zza
living
Zeeuws
zea
living
Zhuang
zha
living
Zulu
zul
living
Attribution
The classifier has been trained by reading texts in many different languages. Finding high quality, non noisy texts is really difficult. Many thanks to
We have updated the daily quota limits for the different accounts. If you already (before 3rd of March 2017) are subscribing on an account this will not affect you.
The adjustments are made after looking at the statistics of our users. Before the Indie and Professional account had the same rate limits but at different prices. The new model is a ladder from Indie to Professional accounts, with growing discount the higher you get.
This also affected our translation api, which now gives you 40 characters per call instead of 10.
The new pricing can be found here. We will see how it works out the coming weeks, we might have to make some adjustments.
With the latest version of uClassify we have abandoned the old feature extractor for user trained classifiers. This means that you will get better performance for all new classifier created after 2017-03-26. All already created classifiers won’t be affected.
Background
In the beginning, around 2007, I thought it would be best to allow the users to do preprocessing and use a really simple feature extractor on the server. This feature extractor only separated words by the space character (32 decimal). The idea was that users could preprocess their texts to allow more delimiters (e.g. exchange ! to space on their side). You can also generate your own bigrams by combining them with underscore or something.
Classifiers made by uClassify have used other feature extractors, e.g. the sentiment classifier uses unigrams, bigrams, some stemming and converting to lower case. This improves the performance significantly.
Now, it’s not easy for someone who is new to machine learning and text classification to guess which delimiters to use. Also it can be very counter intuitive. For that reason, I decided to replace the old unigram feature extractor with a new high performance general purpose extractor.
The new feature extractor
The new feature extractor has been found heuristically by running extensive tests over a large set of corpora. The datasets are a part of our internal testing suite that contains over 80 different test sets for a wide range of problems. Therefore I am very confident that the new feature extractor will do really well.
In short here is what it does:
convert text to lower case
separate words on white spaces, exclamation mark, parentheses, period and slash.
generate uni grams
generate bi grams
generate parts of long unigrams
This is similar to what the Sentiment classifier has been using which allows it to differentiate between “I don’t like” and “I like”.
Let me know if you have any feedback, you can reach me at contact AT uclassify DOT com or @jonkagstrom on twitter!
Did you know there’s a way to classify texts without having to leave Excel? We have paired up with SeoTools for Excel, a Swiss army knife Excel-plugin, which offers a tailored “Connector” for all uClassify users.
In this blog post, we will show how SeoTools allows you to classify lists of texts or URLs with the classifiers of your choice, and having the results ready for analysis in a matter of seconds.
Don’t be worried if your Excel spreadsheet doesn’t look as the example above. The extra ribbon tab “SeoTools” is added when SeoTools for Excel is installed. At the end of this post you find all the links necessary to setup your uClassify account.
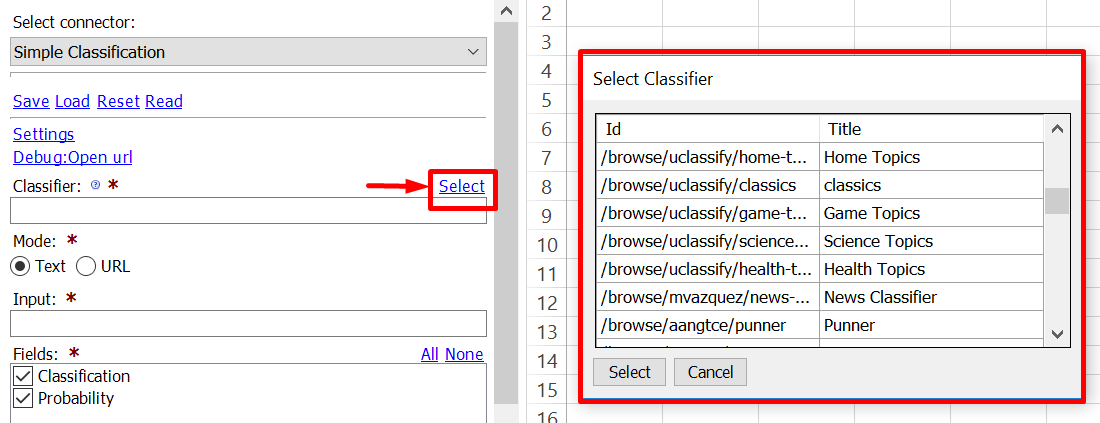
Selecting a classifier
The uClassify Connector is, as the name suggests, connected to uClassify library. Clicking on “Select” opens a window of all available classifiers. It is also possible to choose input type (Text or URL) and if the results include classification and probability.
When you are satisfied with your settings, click “Insert”, and SeoTools will generate the data in columns A and onwards.
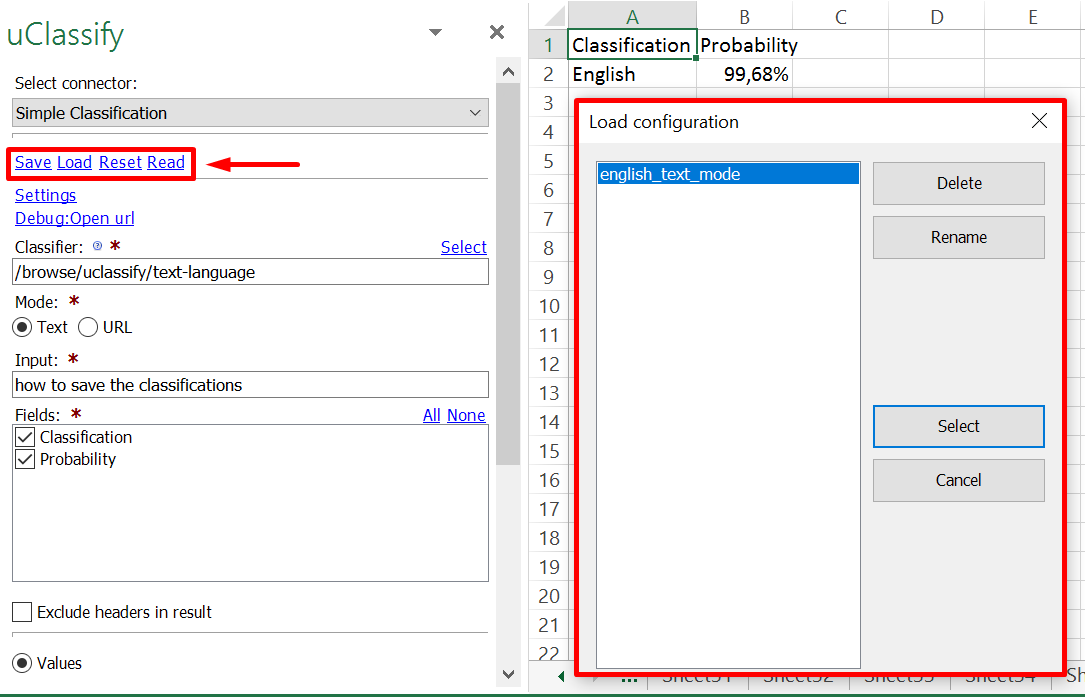
Save time and automate the process
Exporting and filtering Excel data from web based platforms takes time, especially if it’s required on a daily or weekly basis. The filtering part of standardized files is also associated with human error. SeoTools solves this with saving and loading of “Configurations”:
Next time, just load a previous configuration and you will get classifications based on the same settings as last time.
Use Formula Mode to supercharge your classification
The beauty of combining uClassify with Excel is the ability to create large numbers of requests automatically. Instead of populating cells with values, select “Formula” before Inserting the results:
Next, you can change the formula to reference a cell and the uClassify Connector will generate results based on the value or text in that cell.
In the following example, company A has been mentioned 100 times on Twitter in the last week and we want to determine the text Language and Sentiment for these tweets.
First, select the Text Language Classifier and enter a random character in the Input field (we will change this in the formula to reference the tweets). Also, don’t forget select “Exclude headers in result” since we only want the values for each row.
When the formula has been inserted in cell C2, change the input “y” to B2, and SeoTools will return the language with the highest probability. Repeat the same steps for the Sentiment classifier, but insert it in cell D2. It should look like this:
To get the results for all rows, select cell C2 and D2 and drag the formula down and SeoTools will generate the classifications for all tweets. In the example below, we’ve started on row 16 to illustrate the results:
Do you want to try it with your uClassify account?
⦁ Sign up for a 14-Day Trial and follow the instructions to download and install the latest version of SeoTools.
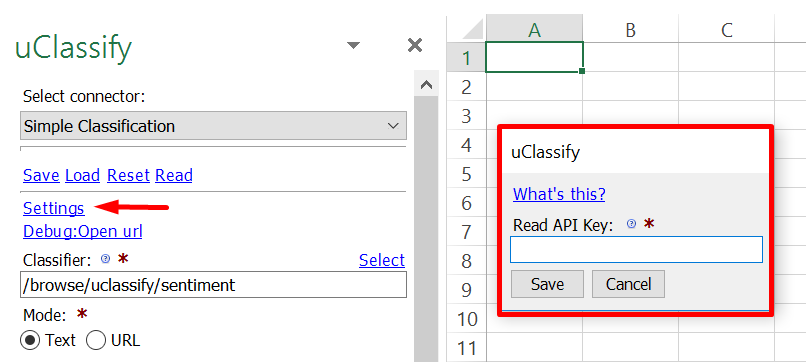
⦁ Register your access key under “Upgrade to Pro” and access uClassify in the Connectors menu:
⦁ Next, go to API keys in the top menu of your uClassify account and copy the Read key
⦁ Finally, copy your API-key and paste it in the “Options” menu:
The complete documentation of the uClassify Connector features can be found here.
If you have any questions, feedback, or suggestions about ways to improve the Connector, please contact victor@seotoolsforexcel.com.
A brief introduction to our machine translation algorithm
We have implemented statistical machine translation (SMT). SMT is completely data driven. It works by calculating word and phrase probabilities from a large corpus. We have used OPUS and Wiktionary as our primary sources.
Data models
From the data sources (mostly bilingual parallel language sets) a dictionary of translations is constructed. For each translation we keep a count and parts of speech tags for both source and target, this is our translation model & pos models and it looks something like:
Translation & pos models
source word|source pos tags|translation count|target word |target pos tags
om|conj|12|if|conj
om|adv|7|again|adj
övermorgon|adv|3|the day after tomorrow|det noun prep noun
...
For the target language a language model and a grammar model is used. Each consists of 1-5 n grams. The language model consists of word sequences and a frequency, the grammar model of pos tags and their frequencies:
Language model
phrase|count
hello word|493920
hi world|19444
...
Grammar model
pos tags|count
prep noun|454991
prep prep|3183
...
Building a graph
So we have data. Plenty of data. Now we just need to make use of it. When a text is translated a graph is built between all possible translations, most of the time each word has multiple translations and meanings, so the number of combinations grows very quickly. During the graph building we need to remember that source phrases can contract, e.g. ‘i morgon’=>’tomorrow’ and expand ‘övermorgon’=>’the day after tomorrow’.
We look at a maximum of 5 words. Once the graph is built, a traversal is initiated. As we traverse the graph encountered sub phrases are scored and the best path is chosen.
Graph for 'hej världen!'
hej världen !
--------------------------
Translations:
hi world !
hello universe
howdy earth
hey
Combinations:
hi world !
hi universe !
hi earth !
hello world !
hello universe !
hello earth !
...
Unfortunately there is no way to examine all translations so we need to traverse the graph intelligently. We use a beam search with limited depth and width to get the scope down to manageable scales.
Scoring phrases
The scoring of each phrases combines the four aforementioned aspects of the language:
Translation model: This is the dictionary, source->target each entry has a frequency, from the frequency we can calculate a probability (p1) “the most likely translation for ‘hej’ this word is ‘hello'”
Source grammar model: The pos tag helps us to resolve ambiguity, a probability (p2) is calculated, basically saying “‘hej’/’hello’ is likely an interjection”.
Target language model: We look at 1-5 grams. A n-gram is a sequence of words, for example “hello world” is a 2-gram. Each n-gram has a frequency indicating how common it’s. Again a probability (p3) can be calculated, “the sequence ‘hello world’ is more likely than ‘hi world'”.
Target grammar model: just like the language model we do the same but with pos tags. A probability (p4) is calculated indicating “Yeah a verb followed by a preposition sounds better than two prepositions in a row” etc.
We use a sliding window moving over the phrase and combining probabilities using the chain rule into accumulated P1-P4. We end up with 4 parameters that are finally mixed with different weights according to
score=P1^w1*P2^w2*P3^w3*P4^w4
Working in log space makes life easier here. Then we just select the phrase with the highest score.
We estimate the weights (w1-w4) by a randomized search that tries to maximize a bleu-score for a test set. The estimation only needs to be rerun when the training data changes. As expected, the most important (highest weight) is assigned the translation model (w1=1), second highest the source grammar model (w3~0.6), third highest the language model (w2~0.3) and finally the target grammar model (w4~0.05). Yes, the as it turns out the target grammar model is not very important, it helps to resolve uncertainty in some cases by predicting pos tags. But I might actually nuke it to favor simplicity in future versions.
There were plenty of unmentioned problems to be solved along the way, but you get the overall idea. One thing that easily puts you off is the size of the data you are dealing with. E.g. downloading TB sized datasets like the google ngrams and processing those. At one point, after 4 days processing those huge zipfiles, Windows Update decided to restart the computer…
We get a lot of requests for classifiers in different languages and as a next step we are building a translation API. The idea is to have an affordable in-house machine translation service that can quickly translate requests to the classifier language, classify the request and send back the response. Since the majority of classifiers are in English, the primary focus will be to target English.
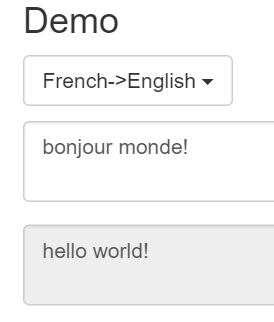
Initially we support French, Spanish and Swedish to English translations.
Translation demo
The API is accessible with your ordinary API read key and a GET/POST REST protocol.
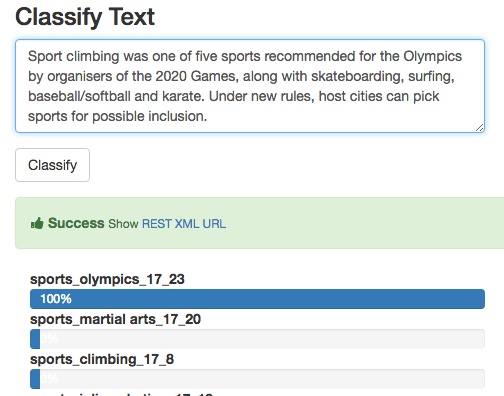
Upon popular request I’ve built a new topics classifier based on the IAB taxonomy. EDIT: We also support the IAB Taxonomy V2 now.
The classifier has two levels of depth, a main category (sports, science…) and a sub category (soccer, physics…). In total there are about 360 different classes following the IAB Quality Assurance Guidelines (QAG) Taxonomy specification.
The class names are composed of 4 parts separated by an underscore, with the following structure:
main topic_sub topic_main id_sub id home and garden_flowers_5_4 sports_climbing_17_3 sports_volleyball_17_7
The last two ids are the IAB ids, this will make it easier for users tho map and integrate the result.
With a free uClassify account you can make 1000 free calls per day, if you need more there are affordable options from 9€ per month. You can sign up here.
List of topics
IAB12 News and IAB24 Uncategorized is not supported.
IAB1 Arts & Entertainment
IAB1-1 Books & Literature
IAB1-2 Celebrity Fan/Gossip
IAB1-3 Fine Art
IAB1-4 Humor
IAB1-5 Movies
IAB1-6 Music
IAB1-7 Television
IAB2 Automotive
IAB2-1 Auto Parts
IAB2-2 Auto Repair
IAB2-3 Buying/Selling Cars
IAB2-4 Car Culture
IAB2-5 Certified Pre-Owned
IAB2-6 Convertible
IAB2-7 Coupe
IAB2-8 Crossover
IAB2-9 Diesel
IAB2-10 Electric Vehicle
IAB2-11 Hatchback
IAB2-12 Hybrid
IAB2-13 Luxury
IAB2-14 Minivan
IAB2-15 Motorcycles
IAB2-16 Off-Road Vehicles
IAB2-17 Performance Vehicles
IAB2-18 Pickup
IAB2-19 Road-Side Assistance
IAB2-20 Sedan
IAB2-21 Trucks & Accessories
IAB2-22 Vintage Cars
IAB2-23 Wagon
IAB3 Business
IAB3-1 Advertising
IAB3-2 Agriculture
IAB3-3 Biotech/Biomedical
IAB3-4 Business Software
IAB3-5 Construction
IAB3-6 Forestry
IAB3-7 Government
IAB3-8 Green Solutions
IAB3-9 Human Resources
IAB3-10 Logistics
IAB3-11 Marketing
IAB3-12 Metals
IAB4 Careers
IAB4-1 Career Planning
IAB4-2 College
IAB4-3 Financial Aid
IAB4-4 Job Fairs
IAB4-5 Job Search
IAB4-6 Resume Writing/Advice
IAB4-7 Nursing
IAB4-8 Scholarships
IAB4-9 Telecommuting
IAB4-10 U.S. Military
IAB4-11 Career Advice
IAB5 Education
IAB5-1 7-12 Education
IAB5-2 Adult Education
IAB5-3 Art History
IAB5-4 College Administration
IAB5-5 College Life
IAB5-6 Distance Learning
IAB5-7 English as a 2nd Language
IAB5-8 Language Learning
IAB5-9 Graduate School
IAB5-10 Homeschooling
IAB5-11 Homework/Study Tips
IAB5-12 K-6 Educators
IAB5-13 Private School
IAB5-14 Special Education
IAB5-15 Studying Business
IAB6 Family & Parenting
IAB6-1 Adoption
IAB6-2 Babies & Toddlers
IAB6-3 Daycare/Pre School
IAB6-4 Family Internet
IAB6-5 Parenting – K-6 Kids
IAB6-6 Parenting teens
IAB6-7 Pregnancy
IAB6-8 Special Needs Kids
IAB6-9 Eldercare
IAB7 Health & Fitness
IAB7-1 Exercise
IAB7-2 ADD
IAB7-3 AIDS/HIV
IAB7-4 Allergies
IAB7-5 Alternative Medicine
IAB7-6 Arthritis
IAB7-7 Asthma
IAB7-8 Autism/PDD
IAB7-9 Bipolar Disorder
IAB7-10 Brain Tumor
IAB7-11 Cancer
IAB7-12 Cholesterol
IAB7-13 Chronic Fatigue Syndrome
IAB7-14 Chronic Pain
IAB7-15 Cold & Flu
IAB7-16 Deafness
IAB7-17 Dental Care
IAB7-18 Depression
IAB7-19 Dermatology
IAB7-20 Diabetes
IAB7-21 Epilepsy
IAB7-22 GERD/Acid Reflux
IAB7-23 Headaches/Migraines
IAB7-24 Heart Disease
IAB7-25 Herbs for Health
IAB7-26 Holistic Healing
IAB7-27 IBS/Crohn’s Disease
IAB7-28 Incest/Abuse Support
IAB7-29 Incontinence
IAB7-30 Infertility
IAB7-31 Men’s Health
IAB7-32 Nutrition
IAB7-33 Orthopedics
IAB7-34 Panic/Anxiety Disorders
IAB7-35 Pediatrics
IAB7-36 Physical Therapy
IAB7-37 Psychology/Psychiatry
IAB7-38 Senior Health
IAB7-39 Sexuality
IAB7-40 Sleep Disorders
IAB7-41 Smoking Cessation
IAB7-42 Substance Abuse
IAB7-43 Thyroid Disease
IAB7-44 Weight Loss
IAB7-45 Women’s Health
IAB8 Food & Drink
IAB8-1 American Cuisine
IAB8-2 Barbecues & Grilling
IAB8-3 Cajun/Creole
IAB8-4 Chinese Cuisine
IAB8-5 Cocktails/Beer
IAB8-6 Coffee/Tea
IAB8-7 Cuisine-Specific
IAB8-8 Desserts & Baking
IAB8-9 Dining Out
IAB8-10 Food Allergies
IAB8-11 French Cuisine
IAB8-12 Health/Low-Fat Cooking
IAB8-13 Italian Cuisine
IAB8-14 Japanese Cuisine
IAB8-15 Mexican Cuisine
IAB8-16 Vegan
IAB8-17 Vegetarian
IAB8-18 Wine
IAB9 Hobbies & Interests
IAB9-1 Art/Technology
IAB9-2 Arts & Crafts
IAB9-3 Beadwork
IAB9-4 Bird-Watching
IAB9-5 Board Games/Puzzles
IAB9-6 Candle & Soap Making
IAB9-7 Card Games
IAB9-8 Chess
IAB9-9 Cigars
IAB9-10 Collecting
IAB9-11 Comic Books
IAB9-12 Drawing/Sketching
IAB9-13 Freelance Writing
IAB9-14 Genealogy
IAB9-15 Getting Published
IAB9-16 Guitar
IAB9-17 Home Recording
IAB9-18 Investors & Patents
IAB9-19 Jewelry Making
IAB9-20 Magic & Illusion
IAB9-21 Needlework
IAB9-22 Painting
IAB9-23 Photography
IAB9-24 Radio
IAB9-25 Roleplaying Games
IAB9-26 Sci-Fi & Fantasy
IAB9-27 Scrapbooking
IAB9-28 Screenwriting
IAB9-29 Stamps & Coins
IAB9-30 Video & Computer Games
IAB9-31 Woodworking
IAB10 Home & Garden
IAB10-1 Appliances
IAB10-2 Entertaining
IAB10-3 Environmental Safety
IAB10-4 Gardening
IAB10-5 Home Repair
IAB10-6 Home Theater
IAB10-7 Interior Decorating
IAB10-8 Landscaping
IAB10-9 Remodeling & Construction
IAB11 Law, Government, & Politics
IAB11-1 Immigration
IAB11-2 Legal Issues
IAB11-3 U.S. Government Resources
IAB11-4 Politics
IAB11-5 Commentary
IAB12 News*
IAB12-1 International News
IAB12-2 National News
IAB12-3 Local News
IAB14 Society
IAB14-1 Dating
IAB14-2 Divorce Support
IAB14-3 Gay Life
IAB14-4 Marriage
IAB14-5 Senior Living
IAB14-6 Teens
IAB14-7 Weddings
IAB14-8 Ethnic Specific
IAB16 Pets
IAB16-1 Aquariums
IAB16-2 Birds
IAB16-3 Cats
IAB16-4 Dogs
IAB16-5 Large Animals
IAB16-6 Reptiles
IAB16-7 Veterinary Medicine
IAB17 Sports
IAB17-1 Auto Racing
IAB17-2 Baseball
IAB17-3 Bicycling
IAB17-4 Bodybuilding
IAB17-5 Boxing
IAB17-6 Canoeing/Kayaking
IAB17-7 Cheerleading
IAB17-8 Climbing
IAB17-9 Cricket
IAB17-10 Figure Skating
IAB17-11 Fly Fishing
IAB17-12 Football
IAB17-13 Freshwater Fishing
IAB17-14 Game & Fish
IAB17-15 Golf
IAB17-16 Horse Racing
IAB17-17 Horses
IAB17-18 Hunting/Shooting
IAB17-19 Inline Skating
IAB17-20 Martial Arts
IAB17-21 Mountain Biking
IAB17-22 NASCAR Racing
IAB17-23 Olympics
IAB17-24 Paintball
IAB17-25 Power & Motorcycles
IAB17-26 Pro Basketball
IAB17-27 Pro Ice Hockey
IAB17-28 Rodeo
IAB17-29 Rugby
IAB17-30 Running/Jogging
IAB17-31 Sailing
IAB17-32 Saltwater Fishing
IAB17-33 Scuba Diving
IAB17-34 Skateboarding
IAB17-35 Skiing
IAB17-36 Snowboarding
IAB17-37 Surfing/Body-Boarding
IAB17-38 Swimming
IAB17-39 Table Tennis/Ping-Pong
IAB17-40 Tennis
IAB17-41 Volleyball
IAB17-42 Walking
IAB17-43 Waterski/Wakeboard
IAB17-44 World Soccer
IAB18 Style & Fashion
IAB18-1 Beauty
IAB18-2 Body Art
IAB18-3 Fashion
IAB18-4 Jewelry
IAB18-5 Clothing
IAB18-6 Accessories
IAB19 Technology & Computing
IAB19-1 3-D Graphics
IAB19-2 Animation
IAB19-3 Antivirus Software
IAB19-4 C/C++
IAB19-5 Cameras & Camcorders
IAB19-6 Cell Phones
IAB19-7 Computer Certification
IAB19-8 Computer Networking
IAB19-9 Computer Peripherals
IAB19-10 Computer Reviews
IAB19-11 Data Centers
IAB19-12 Databases
IAB19-13 Desktop Publishing
IAB19-14 Desktop Video
IAB19-15 Email
IAB19-16 Graphics Software
IAB19-17 Home Video/DVD
IAB19-18 Internet Technology
IAB19-19 Java
IAB19-20 JavaScript
IAB19-21 Mac Support
IAB19-22 MP3/MIDI
IAB19-23 Net Conferencing
IAB19-24 Net for Beginners
IAB19-25 Network Security
IAB19-26 Palmtops/PDAs
IAB19-27 PC Support
IAB19-28 Portable
IAB19-29 Entertainment
IAB19-30 Shareware/Freeware
IAB19-31 Unix
IAB19-32 Visual Basic
IAB19-33 Web Clip Art
IAB19-34 Web Design/HTML
IAB19-35 Web Search
IAB19-36 Windows
IAB20 Travel
IAB20-1 Adventure Travel
IAB20-2 Africa
IAB20-3 Air Travel
IAB20-4 Australia & New Zealand
IAB20-5 Bed & Breakfasts
IAB20-6 Budget Travel
IAB20-7 Business Travel
IAB20-8 By US Locale
IAB20-9 Camping
IAB20-10 Canada
IAB20-11 Caribbean
IAB20-12 Cruises
IAB20-13 Eastern Europe
IAB20-14 Europe
IAB20-15 France
IAB20-16 Greece
IAB20-17 Honeymoons/Getaways
IAB20-18 Hotels
IAB20-19 Italy
IAB20-20 Japan
IAB20-21 Mexico & Central America
IAB20-22 National Parks
IAB20-23 South America
IAB20-24 Spas
IAB20-25 Theme Parks
IAB20-26 Traveling with Kids
IAB20-27 United Kingdom
IAB21 Real Estate
IAB21-1 Apartments
IAB21-2 Architects
IAB21-3 Buying/Selling Homes
A new keywords API was released a few weeks ago. The old one was not really well designed and needed a revamp.
With the keywords API you can extract keywords from texts with respect to a classifier, for example, if you want to find words that make a text positive or negative you extract keywords with the sentiment classifier or if you want to generate tags for a blog post based on topic, you can run it through a topics classifier or maybe our new IAB Taxonomy classifier.
The result will be a lists of keywords where each keywords is associated with one of the classes. Also each keywords has a probablility, indicating how important each keyword is, a weight if you will. A high value (max 1) means the keyword is very important/relevant.
Example result when extracting text from the sentiment classifier:
The new URL REST API is our simplest to use API. You can copy paste the API url in the browser and get the result. The read api key and text are passed as parameters in the url.
The result is simply a JSON dictionary with class=>probabilities:
{
"negative": 0.133639,
"positive": 0.866361
}
The only thing you need to do is to sign up for a free account (allows you 1000 calls per day) and replace ‘YOUR_READ_API_KEY_HERE’ with your read api key (found after you log in).
Here is the documentation for the api. The API is a simplified subset of our standard JSON REST API, you can read more the uClassify API differences here.