We have constructed a language detector consisting of about 374 languages.
It can detect both living and extinct languages (e.g. English and Tupi), identify ancient and constructed (e.g. Latin and Klingon) and even different dialects.
Each language class has been named with its English name followed by an underscore and the corresponding ISO 639-3 three letter code. E.g.
- Swedish_swe
- English_eng
- Chinese_zho
- Mesopotamian Arabic_acm
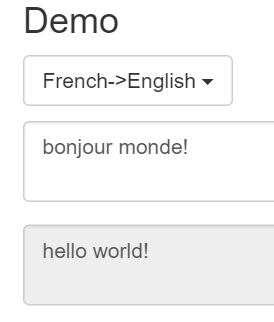
You can try it here, it needs a few words to make accurate detections.
Some of the rare languages (about 30) may have insufficient training data. The idea is to improve the classifier as more documents are gathered. Also we may add more languages in the future, so make sure your code can handle that.
Here is the full list of supported languages
| Language Name | ISO 639-3 | Type |
| Abkhazian | abk | living |
| Achinese | ace | living |
| Adyghe | ady | living |
| Afrihili | afh | constructed |
| Afrikaans | afr | living |
| Ainu | ain | living |
| Akan | aka | living |
| Albanian | sqi | living |
| Algerian Arabic | arq | living |
| Amharic | amh | living |
| Ancient Greek | grc | historical |
| Arabic | ara | living |
| Aragonese | arg | living |
| Armenian | hye | living |
| Arpitan | frp | living |
| Assamese | asm | living |
| Assyrian Neo-Aramaic | aii | living |
| Asturian | ast | living |
| Avaric | ava | living |
| Awadhi | awa | living |
| Aymara | aym | living |
| Azerbaijani | aze | living |
| Balinese | ban | living |
| Bambara | bam | living |
| Banjar | bjn | living |
| Bashkir | bak | living |
| Basque | eus | living |
| Bavarian | bar | living |
| Baybayanon | bvy | living |
| Belarusian | bel | living |
| Bengali | ben | living |
| Berber | ber | living |
| Bhojpuri | bho | living |
| Bishnupriya | bpy | living |
| Bislama | bis | living |
| Bodo | brx | living |
| Bosnian | bos | living |
| Breton | bre | living |
| Bulgarian | bul | living |
| Buriat | bua | living |
| Burmese | mya | living |
| Catalan | cat | living |
| Cebuano | ceb | living |
| Central Bikol | bcl | living |
| Central Huasteca Nahuatl | nch | living |
| Central Khmer | khm | living |
| Central Kurdish | ckb | living |
| Central Mnong | cmo | living |
| Chamorro | cha | living |
| Chavacano | cbk | living |
| Chechen | che | living |
| Cherokee | chr | living |
| Chinese | zho | living |
| Choctaw | cho | living |
| Chukot | ckt | living |
| Church Slavic | chu | ancient |
| Chuvash | chv | living |
| Coastal Kadazan | kzj | living |
| Cornish | cor | living |
| Corsican | cos | living |
| Cree | cre | living |
| Crimean Tatar | crh | living |
| Croatian | hrv | living |
| Cuyonon | cyo | living |
| Czech | ces | living |
| Danish | dan | living |
| Dhivehi | div | living |
| Dimli | diq | living |
| Dungan | dng | living |
| Dutch | nld | living |
| Dutton World Speedwords | dws | constructed |
| Dzongkha | dzo | living |
| Eastern Mari | mhr | living |
| Egyptian Arabic | arz | living |
| Emilian | egl | living |
| English | eng | living |
| Erzya | myv | living |
| Esperanto | epo | constructed |
| Estonian | est | living |
| Ewe | ewe | living |
| Extremaduran | ext | living |
| Faroese | fao | living |
| Fiji Hindi | hif | living |
| Finnish | fin | living |
| French | fra | living |
| Friulian | fur | living |
| Fulah | ful | living |
| Gagauz | gag | living |
| Galician | glg | living |
| Gan Chinese | gan | living |
| Ganda | lug | living |
| Garhwali | gbm | living |
| Georgian | kat | living |
| German | deu | living |
| Gilaki | glk | living |
| Gilbertese | gil | living |
| Goan Konkani | gom | living |
| Gothic | got | ancient |
| Guarani | grn | living |
| Guerrero Nahuatl | ngu | living |
| Gujarati | guj | living |
| Gulf Arabic | afb | living |
| Haitian | hat | living |
| Hakka Chinese | hak | living |
| Hausa | hau | living |
| Hawaiian | haw | living |
| Hebrew | heb | living |
| Hiligaynon | hil | living |
| Hindi | hin | living |
| Hmong Daw | mww | living |
| Hmong Njua | hnj | living |
| Ho | hoc | living |
| Hungarian | hun | living |
| Iban | iba | living |
| Icelandic | isl | living |
| Ido | ido | constructed |
| Igbo | ibo | living |
| Iloko | ilo | living |
| Indonesian | ind | living |
| Ingrian | izh | living |
| Interlingua | ina | constructed |
| Interlingue | ile | constructed |
| Iranian Persian | pes | living |
| Irish | gle | living |
| Italian | ita | living |
| Jamaican Creole English | jam | living |
| Japanese | jpn | living |
| Javanese | jav | living |
| Jinyu Chinese | cjy | living |
| Judeo-Tat | jdt | living |
| K’iche’ | quc | living |
| Kabardian | kbd | living |
| Kabyle | kab | living |
| Kadazan Dusun | dtp | living |
| Kalaallisut | kal | living |
| Kalmyk | xal | living |
| Kamba | kam | living |
| Kannada | kan | living |
| Kara-Kalpak | kaa | living |
| Karachay-Balkar | krc | living |
| Karelian | krl | living |
| Kashmiri | kas | living |
| Kashubian | csb | living |
| Kazakh | kaz | living |
| Kekchķ | kek | living |
| Keningau Murut | kxi | living |
| Khakas | kjh | living |
| Khasi | kha | living |
| Kinyarwanda | kin | living |
| Kirghiz | kir | living |
| Klingon | tlh | constructed |
| Kölsch | ksh | living |
| Komi | kom | living |
| Komi-Permyak | koi | living |
| Komi-Zyrian | kpv | living |
| Kongo | kon | living |
| Korean | kor | living |
| Kotava | avk | constructed |
| Kumyk | kum | living |
| Kurdish | kur | living |
| Ladin | lld | living |
| Ladino | lad | living |
| Lakota | lkt | living |
| Lao | lao | living |
| Latgalian | ltg | living |
| Latin | lat | ancient |
| Latvian | lav | living |
| Laz | lzz | living |
| Lezghian | lez | living |
| Lįadan | ldn | constructed |
| Ligurian | lij | living |
| Lingala | lin | living |
| Lingua Franca Nova | lfn | constructed |
| Literary Chinese | lzh | historical |
| Lithuanian | lit | living |
| Liv | liv | living |
| Livvi | olo | living |
| Lojban | jbo | constructed |
| Lombard | lmo | living |
| Louisiana Creole | lou | living |
| Low German | nds | living |
| Lower Sorbian | dsb | living |
| Luxembourgish | ltz | living |
| Macedonian | mkd | living |
| Madurese | mad | living |
| Maithili | mai | living |
| Malagasy | mlg | living |
| Malay | zlm | living |
| Malay | msa | living |
| Malayalam | mal | living |
| Maltese | mlt | living |
| Mambae | mgm | living |
| Mandarin Chinese | cmn | living |
| Manx | glv | living |
| Maori | mri | living |
| Marathi | mar | living |
| Marshallese | mah | living |
| Mazanderani | mzn | living |
| Mesopotamian Arabic | acm | living |
| Mi’kmaq | mic | living |
| Middle English | enm | historical |
| Middle French | frm | historical |
| Min Nan Chinese | nan | living |
| Minangkabau | min | living |
| Mingrelian | xmf | living |
| Mirandese | mwl | living |
| Modern Greek | ell | living |
| Mohawk | moh | living |
| Moksha | mdf | living |
| Mon | mnw | living |
| Mongolian | mon | living |
| Morisyen | mfe | living |
| Moroccan Arabic | ary | living |
| Na | nbt | living |
| Narom | nrm | living |
| Nauru | nau | living |
| Navajo | nav | living |
| Neapolitan | nap | living |
| Nepali | npi | living |
| Nepali | nep | living |
| Newari | new | living |
| Ngeq | ngt | living |
| Nigerian Fulfulde | fuv | living |
| Niuean | niu | living |
| Nogai | nog | living |
| North Levantine Arabic | apc | living |
| North Moluccan Malay | max | living |
| Northern Frisian | frr | living |
| Northern Luri | lrc | living |
| Northern Sami | sme | living |
| Norwegian | nor | living |
| Norwegian Bokmål | nob | living |
| Norwegian Nynorsk | nno | living |
| Novial | nov | constructed |
| Nyanja | nya | living |
| Occitan | oci | living |
| Official Aramaic | arc | ancient |
| Ojibwa | oji | living |
| Old Aramaic | oar | ancient |
| Old English | ang | historical |
| Old Norse | non | historical |
| Old Russian | orv | historical |
| Old Saxon | osx | historical |
| Oriya | ori | living |
| Orizaba Nahuatl | nlv | living |
| Oromo | orm | living |
| Ossetian | oss | living |
| Ottoman Turkish | ota | historical |
| Palauan | pau | living |
| Pampanga | pam | living |
| Pangasinan | pag | living |
| Panjabi | pan | living |
| Papiamento | pap | living |
| Pedi | nso | living |
| Pennsylvania German | pdc | living |
| Persian | fas | living |
| Pfaelzisch | pfl | living |
| Picard | pcd | living |
| Piemontese | pms | living |
| Pipil | ppl | living |
| Pitcairn-Norfolk | pih | living |
| Polish | pol | living |
| Pontic | pnt | living |
| Portuguese | por | living |
| Prussian | prg | living |
| Pulaar | fuc | living |
| Pushto | pus | living |
| Quechua | que | living |
| Quenya | qya | constructed |
| Romanian | ron | living |
| Romansh | roh | living |
| Romany | rom | living |
| Rundi | run | living |
| Russia Buriat | bxr | living |
| Russian | rus | living |
| Rusyn | rue | living |
| Samoan | smo | living |
| Samogitian | sgs | living |
| Sango | sag | living |
| Sanskrit | san | ancient |
| Sardinian | srd | living |
| Saterfriesisch | stq | living |
| Scots | sco | living |
| Scottish Gaelic | gla | living |
| Serbian | srp | living |
| Serbo-Croatian | hbs | living |
| Seselwa Creole French | crs | living |
| Shona | sna | living |
| Shuswap | shs | living |
| Sicilian | scn | living |
| Silesian | szl | living |
| Sindarin | sjn | constructed |
| Sindhi | snd | living |
| Sinhala | sin | living |
| Slovak | slk | living |
| Slovenian | slv | living |
| Somali | som | living |
| South Azerbaijani | azb | living |
| Southern Sami | sma | living |
| Southern Sotho | sot | living |
| Spanish | spa | living |
| Sranan Tongo | srn | living |
| Standard Latvian | lvs | living |
| Standard Malay | zsm | living |
| Sumerian | sux | ancient |
| Sundanese | sun | living |
| Swabian | swg | living |
| Swahili | swa | living |
| Swahili | swh | living |
| Swati | ssw | living |
| Swedish | swe | living |
| Swiss German | gsw | living |
| Tagal Murut | mvv | living |
| Tagalog | tgl | living |
| Tahitian | tah | living |
| Tajik | tgk | living |
| Talossan | tzl | constructed |
| Talysh | tly | living |
| Tamil | tam | living |
| Tarifit | rif | living |
| Tase Naga | nst | living |
| Tatar | tat | living |
| Telugu | tel | living |
| Temuan | tmw | living |
| Tetum | tet | living |
| Thai | tha | living |
| Tibetan | bod | living |
| Tigrinya | tir | living |
| Tok Pisin | tpi | living |
| Tokelau | tkl | living |
| Tonga | ton | living |
| Tosk Albanian | als | living |
| Tsonga | tso | living |
| Tswana | tsn | living |
| Tulu | tcy | living |
| Tupķ | tpw | extinct |
| Turkish | tur | living |
| Turkmen | tuk | living |
| Tuvalu | tvl | living |
| Tuvinian | tyv | living |
| Udmurt | udm | living |
| Uighur | uig | living |
| Ukrainian | ukr | living |
| Umbundu | umb | living |
| Upper Sorbian | hsb | living |
| Urdu | urd | living |
| Urhobo | urh | living |
| Uzbek | uzb | living |
| Venda | ven | living |
| Venetian | vec | living |
| Veps | vep | living |
| Vietnamese | vie | living |
| Vlaams | vls | living |
| Vlax Romani | rmy | living |
| Volapük | vol | constructed |
| Võro | vro | living |
| Walloon | wln | living |
| Waray | war | living |
| Welsh | cym | living |
| Western Frisian | fry | living |
| Western Mari | mrj | living |
| Western Panjabi | pnb | living |
| Wolof | wol | living |
| Wu Chinese | wuu | living |
| Xhosa | xho | living |
| Xiang Chinese | hsn | living |
| Yakut | sah | living |
| Yiddish | yid | living |
| Yoruba | yor | living |
| Yue Chinese | yue | living |
| Zaza | zza | living |
| Zeeuws | zea | living |
| Zhuang | zha | living |
| Zulu | zul | living |
Attribution
The classifier has been trained by reading texts in many different languages. Finding high quality, non noisy texts is really difficult. Many thanks to